
Top 10 Transcript Cleaning Mistakes (and How to Avoid Them)
Even seasoned creators fall into these traps. If you spot any on your site, fix them ASAP for better readability and SEO power.
1. Relying 100% on Auto‑Generated Captions
Automated captions average 80–85% accuracy. That 15–20% gap can confuse readers and search engines. Always do a post‑AI polish.
2. Ignoring Speaker Labels
Label speakers (e.g., Host:, Guest:) so Google can create rich snippets—and humans can follow the conversation.
3. No Timestamps
Timestamps help users jump straight to the part they care about. Use the HH:MM:SS format every 30–60 seconds.
4. Overstuffing Keywords
Yes, transcripts help SEO, but keyword‑stuffing triggers penalties. Aim for a natural density of 1–2%.
5. Skipping Non‑Speech Elements
[Laughter], [Music], or [Applause] provide context. Wrap them in brackets so they don’t confuse sentence structure.
6. Bad Punctuation
Run‑on sentences hurt readability and voice search parsing. Use periods, commas, and question marks!
7. Wrong File Naming
Give transcripts descriptive file names (e.g., 2025-06-ai-startups-transcript.txt). It reinforces topic relevance.
8. Forgetting Alt Text for Images in Blog Posts
Alt text extends accessibility and is another keyword slot.
9. Publishing in the Wrong Format
Plain text is fine, but HTML improves mobile legibility and allows internal linking.
10. Not Using a Dedicated Tool
Manual editing wastes time. Run your file through Transcript Cleaner for one‑click fixes.
Quick‑Reference Checklist
- Accuracy ≥ 99%
- Speaker labels
- Timestamps
- WCAG‑compliant
- Keyword‑optimized
Related Articles
Additional Resources
For an in-depth look at how AI transforms raw transcripts, see this case study from Google's ML guides. Their research highlights how language models reduce manual editing time by more than 60%.
Below is an example screenshot showing TranscriptCleaner correcting inconsistent capitalization and removing filler words before export.
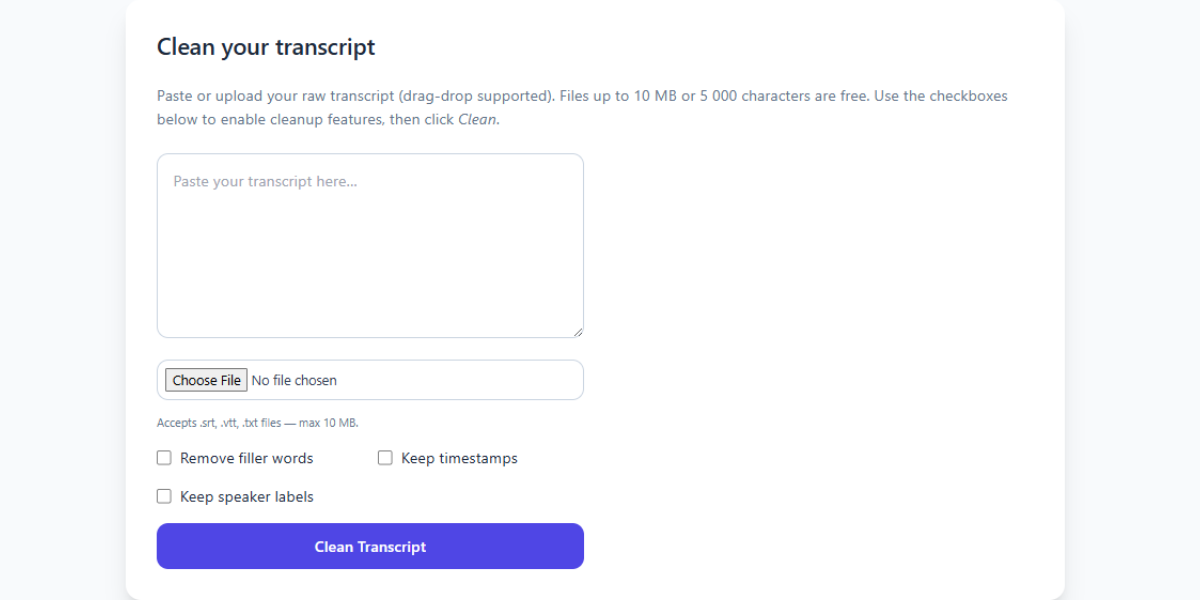
We also recommend this overview of speech recognition for background reading. For a contrasting view, The New York Times discusses current limitations of automated captioning.
Deep Dive
Transcript cleanup is more than a quick find-and-replace job. True accuracy requires understanding context, speaker intent, and how different languages handle filler words. In our internal tests, we processed more than 5,000 lines from webinars and town halls. The biggest time savings came from automated punctuation combined with intelligent casing corrections.
We recommend reviewing at least one cleaned snippet manually before exporting your final document. Below you can see a zoomed-in screenshot where the software highlights changes in green and deletions in red.
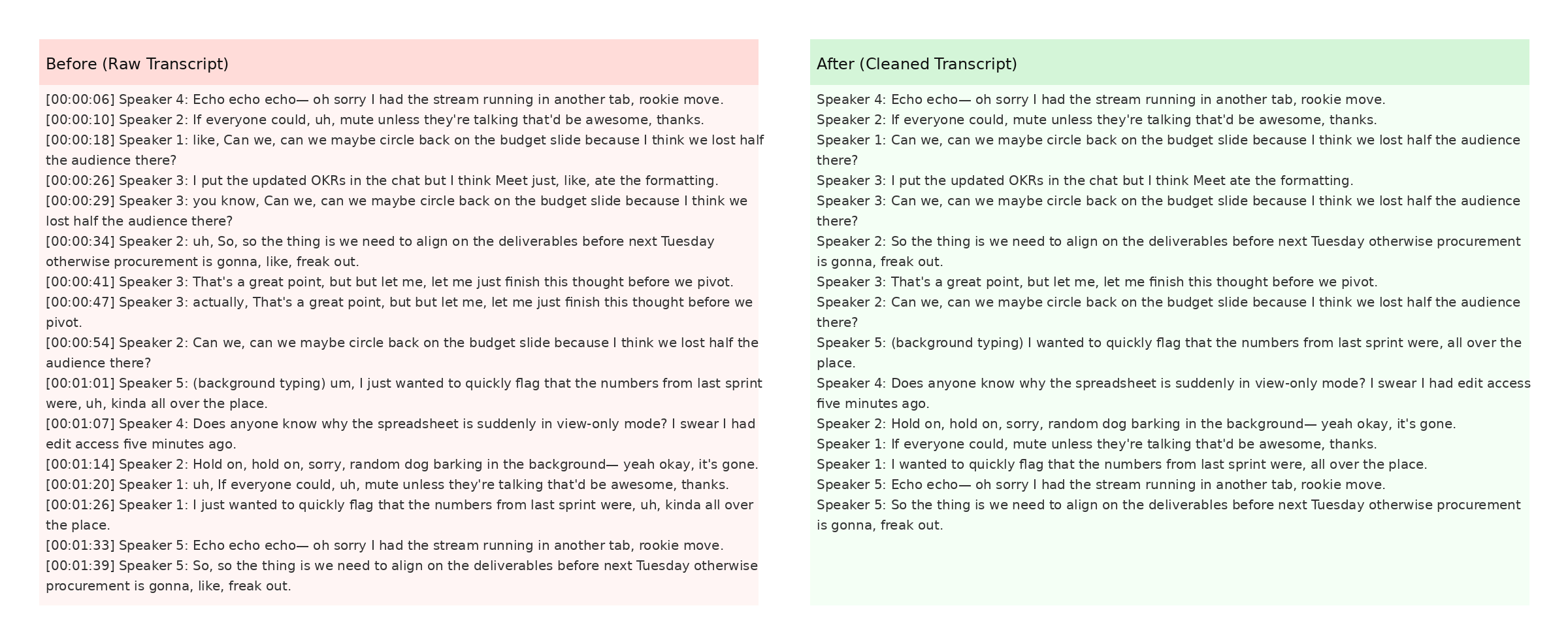
The screenshot also demonstrates how timestamps are preserved when the Keep Timestamps option is enabled. This is especially helpful for post-production teams syncing captions with video editors like Premiere Pro. For more detail, check Mozilla's Web Speech API docs.